
Кратко
СкопированоВ вебе хорошим тоном считается не загружать в браузер ничего лишнего. Например, стили, скрипты и изображения, которые пользователю не понадобятся, можно считать лишними и не загружать. С контентом дело обстоит так же — по возможности мы хотим загружать только то, что пользователю понадобится «прямо сейчас».
В этой статье мы разберёмся, зачем нам это нужно и какие приёмы используются, чтобы этого добиться.
Лишний код
СкопированоСперва поймём, почему мы не хотим держать в проекте лишний код и загружать его в браузер. На это у нас несколько причин.
Трафик дорожает
СкопированоВ первую очередь, ненужный код — это лишний сетевой трафик. Он может быть дорогим, особенно мобильный, особенно в Европе. Сайт или приложение, которые загружают ненужное (особенно изображения), могут оказаться в прямом смысле дорогими.
Время исполнения увеличивается
СкопированоЭто в меньшей степени относится к изображениям и в большей — к JavaScript-файлам. Чем больше JavaScript-кода браузеру необходимо распарсить и выполнить, тем больше времени это займёт. Потраченное время мы украдём у пользователей, пока они будут «ждать загрузки».
Особенно остро это будет досаждать людям с «медленными» устройствами: относительно старыми телефонами или компьютерами. На таких устройствах время исполнения может увеличиваться в разы.
Удобство работы уменьшается
СкопированоЧем больше кода, который не используется, но занимает место, тем больше времени у разработчиков будет уходить на исправление багов и реализацию фич.
Навигация внутри проекта и «загрузка проекта в голову» требуют времени и усилий. Чем больше проект, тем сложнее его охватить и понять. Лишний код только сбивает с мысли и не даёт сосредоточиться на важном.
Код и контент
СкопированоСтратегий борьбы с лишним кодом много: код-сплиттинг и минификация, оптимизация изображений, кэширование, рефакторинг и удаление старого кода.
С контентом ситуация и похожа, и непохожа одновременно. С одной стороны, мы так же не хотим загружать то, что пользователю не нужно, с другой стороны — мы не знаем, что именно пользователю понадобится, и не можем предсказать, на какую страницу он решит перейти. Да и сам контент может постоянно меняться — как в соцсетях.
Поэтому из всех стратегий «сплиттинг» нам подходит больше всего.
Такая стратегия используется уже давно, и скорее всего вы уже встречались с её реализацией в виде пагинаторов.
Пагинаторы
СкопированоКогда сайты были проще, а AJAX и JSON ещё не были распространены, пагинаторы были единственным способом поделить большое количество контента на куски.
Их и сейчас можно встретить, например, на Google.com:

Пример пагинатора.
Когда же JSON и AJAX стали обычным делом, у разработчиков и дизайнеров появилось больше возможностей «делить» контент на части и показывать его пользователю. Одна из таких возможностей — это бесконечный скролл.
Бесконечная прокрутка
СкопированоЧаще всего такой приём можно увидеть в соцсетях: Twitter, Facebook, Instagram и прочих. Когда пользователь докручивает до «конца» страницы, браузер получает от сервера новую порцию постов, и лента становится бесконечной.
Давайте навестим нашу печально известную соцсеть Switter, знакомую нам по статье о безопасности веб-приложений, и поможем её разработчикам создать такую бесконечную загрузку. (Может быть, хотя бы это убережёт их акции от полного краха.)
Switter сейчас
СкопированоСейчас Switter выглядит как лента со свитами и пагинатор внизу.
Наша задача — реализовать бесконечную прокрутку. Нам стоит учесть:
- Switter — маленькая соцсеть, и контент пользователя всё-таки может закончиться. Поэтому нужно предусмотреть ситуацию, когда мы больше не отправляем запросы за новыми порциями.
- Если прокрутка будет работать на страницах, которые видны всем, пользователи могут захотеть поделиться конкретной страницей. Нам нужно сохранять текущую страницу в адресной строке, чтобы ей можно было поделиться.
- Нам не хочется, чтобы пользователи постоянно «упирались» в дно страницы. Поэтому нужно, чтобы «контент уже ждал пользователя», а не наоборот.
Заглушка для сервера
СкопированоПервым делом мы сделаем заглушку для сервера, чтобы имитировать запросы к нему. Для краткости мы скроем шаг с созданием.
Но если вам интересно, как всё устроено — добро пожаловать под капот :–)
Вначале создадим «базу данных».
Это объект поста, которые мы будем отдавать в качестве новой порции контента:
const post = { title: 'Заголовок поста', body: 'Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны.', likes: 77, reposts: 7,}
const post = {
title: 'Заголовок поста',
body:
'Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны.',
likes: 77,
reposts: 7,
}
Теперь создадим «сервер API». Метод posts возвращает Promise, имитируя асинхронное общение между клиентом и сервером («запрос/ответ»). Аргумент page — курсор, номер страницы, которую надо загрузить. С этим номером мы определяем, какую порцию контента отправить. В нашем примере порции отличаться не будут, но в жизни курсор бы влиял на то, какой диапазон постов сервер бы доставал из базы данных. В нашем случае, если текущая страница — 5-я, мы считаем, что контент закончился. Иначе сервер отправляет курсор next. Он указывает, какая страница будет по счёту следующей. Так клиент будет знать, стоит ли ему отправлять запрос за новой порцией контента. В качестве постов отправляем массив из пяти объектов post.
const server = { posts(page = 1) { const finished = page >= 5 const next = finished ? null : page + 1 const posts = Array(5).fill(post) return new Promise((resolve) => { // Таймаут имитирует сетевую «задержку» setTimeout(() => { resolve({ posts, next }) }, 150) }) },}
const server = {
posts(page = 1) {
const finished = page >= 5
const next = finished ? null : page + 1
const posts = Array(5).fill(post)
return new Promise((resolve) => {
// Таймаут имитирует сетевую «задержку»
setTimeout(() => {
resolve({ posts, next })
}, 150)
})
},
}
Вызывать метод для получения новых постов posts мы будем с помощью await:
const response = await server.posts()
const response = await server.posts()
Клиент
СкопированоКогда сервер готов, мы можем приступать к разработке клиентской части. Первым делом спроектируем, как должно работать приложение.
Проектирование
СкопированоМы хотим подгружать новый контент, когда пользователь докручивает до конца страницы. Здесь можно выделить несколько задач:
- Следить за положением прокрутки. Когда мы приближаемся к концу страницы, нужно запрашивать следующую порцию данных.
- Уметь общаться с сервером. Нам нужно отправлять запросы и обрабатывать ответы.
- Преобразовывать данные в вёрстку на странице и отображать её.
- Не забыть о правильной обработке события прокрутки, чтобы ничего не тормозило.
Начнём с вёрстки.
Вёрстка и шаблоны
СкопированоСвит свёрстан как <article>, внутри есть заголовок, текст и кнопки «Нравится» и «Ресвитнуть»:
<article class="post"> <h1>Заголовок поста</h1> <p> Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны. </p> <footer> <button type="button">❤️ 20</button> <button type="button">🔄 20</button> </footer></article>
<article class="post">
<h1>Заголовок поста</h1>
<p>
Текст поста в лучшей на свете социальной сети Switter.
Все совпадения вымышлены и случайны.
</p>
<footer>
<button type="button">❤️ 20</button>
<button type="button">🔄 20</button>
</footer>
</article>
Вёрстка нас устраивает. (<footer> можно заменить на <menu>, но в целом ок.)
Из этой вёрстки мы сделаем шаблон для будущих свитов, которые мы будем загружать с сервера. Шаблон нужен, потому что с сервера мы будем загружать только данные. Как эти данные должны отображаться, сервер не знает. Шаблон будет нужен именно для этого — чтобы браузер мог правильно отобразить данные на странице.
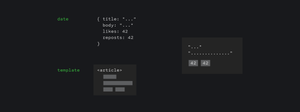
Данные с сервера будут заполнять шаблон, в итоге получится компонент свита. Тег <template> используется, чтобы хранить куски кода, которые не должен видеть пользователь
<template id="post_template"> <!-- Повторяем разметку свита, удаляя все тексты и числа. Оставляем только «скелет» компонента --> <article class="post"> <h2></h2> <p></p> <footer> <button type="button">❤️ </button> <button type="button">🔄 </button> </footer> </article></template>
<template id="post_template">
<!--
Повторяем разметку свита, удаляя все тексты и числа.
Оставляем только «скелет» компонента
-->
<article class="post">
<h2></h2>
<p></p>
<footer>
<button type="button">❤️ </button>
<button type="button">🔄 </button>
</footer>
</article>
</template>
Если мы добавим этот код на страницу, то визуально ничего не изменится, но у нас появится возможность «штамповать» новые свиты с помощью JavaScript-кода. Подробнее об этом мы поговорим чуть ниже.
Отслеживание положения скролла
СкопированоДальше нам потребуется написать функцию, которая будет определять, когда пора отправлять новый запрос. Нам потребуется знать высоту документа и высоту экрана. Они могут отличаться: если на странице много контента, высота документа будет больше высоты экрана (отсюда и скролл). Далее записываем, сколько пикселей пользователь уже проскроллил. После обозначим порог, по приближении к которому будем вызывать какое-то действие. В нашем случае — четверть экрана до конца страницы. Теперь отслеживаем, где находится низ экрана относительно страницы. При пересечении полосы-порога вызываем нужное действие.
function checkPosition() { // Высота документа и экрана const height = document.body.offsetHeight const screenHeight = window.innerHeight // Сколько пикселей уже проскроллили const scrolled = window.scrollY // Порог const threshold = height - screenHeight / 4 // Низ экрана относительно страницы const position = scrolled + screenHeight if (position >= threshold) { // Вызываем действие }}
function checkPosition() {
// Высота документа и экрана
const height = document.body.offsetHeight
const screenHeight = window.innerHeight
// Сколько пикселей уже проскроллили
const scrolled = window.scrollY
// Порог
const threshold = height - screenHeight / 4
// Низ экрана относительно страницы
const position = scrolled + screenHeight
if (position >= threshold) {
// Вызываем действие
}
}
Когда мы докрутим и пересечём порог, отправим запрос за новой порцией контента.
Теперь сделаем эту функцию обработчиком события прокрутки и изменения размера окна:
;(() => { window.addEventListener('scroll', checkPosition) window.addEventListener('resize', checkPosition)})()
;(() => {
window.addEventListener('scroll', checkPosition)
window.addEventListener('resize', checkPosition)
})()
Улучшение производительности
СкопированоОбработку прокрутки стоит немного притормаживать, чтобы она выполнялась чуть реже и таким образом меньше нагружала браузер.
Добавим функцию throttle:
function throttle(callee, timeout) { let timer = null return function perform(...args) { if (timer) return timer = setTimeout(() => { callee(...args) clearTimeout(timer) timer = null }, timeout) }}
function throttle(callee, timeout) {
let timer = null
return function perform(...args) {
if (timer) return
timer = setTimeout(() => {
callee(...args)
clearTimeout(timer)
timer = null
}, timeout)
}
}
И теперь назначим обработчиком событий слегка заторможенную функцию:
;(() => { window.addEventListener('scroll', throttle(checkPosition, 250)) window.addEventListener('resize', throttle(checkPosition, 250))})()
;(() => {
window.addEventListener('scroll', throttle(checkPosition, 250))
window.addEventListener('resize', throttle(checkPosition, 250))
})()
Запросы к серверу
СкопированоДальше создадим функцию для запросов к серверу:
async function fetchPosts() { const { posts, next } = await server.posts(nextPage) // Делаем что-то с posts и next}
async function fetchPosts() {
const { posts, next } = await server.posts(nextPage)
// Делаем что-то с posts и next
}
И используем её в check. Так как fetch асинхронная, check тоже станет асинхронной:
async function checkPosition() { // ...Старый код if (position >= threshold) { await fetchPosts() }}
async function checkPosition() {
// ...Старый код
if (position >= threshold) {
await fetchPosts()
}
}
Обработка данных от сервера
СкопированоВ функции fetch мы получаем список постов, каждый из которых мы хотим добавить на страницу. Напишем функцию append, которая будет этим заниматься. В ней отслеживаем, где находится низ экрана относительно страницы. Ещё используем функцию compose, которую напишем чуть позже — она превращает данные в HTML-элемент.
function appendPost(postData) { // Если данных нет, ничего не делаем if (!postData) return // Храним ссылку на элемент const main = document.querySelector('main') // Превращает данные в HTML-элемент const postNode = composePost(postData) // Добавляем созданный элемент в <main> main.append(postNode)}
function appendPost(postData) {
// Если данных нет, ничего не делаем
if (!postData) return
// Храним ссылку на элемент
const main = document.querySelector('main')
// Превращает данные в HTML-элемент
const postNode = composePost(postData)
// Добавляем созданный элемент в <main>
main.append(postNode)
}
Функция append использует внутри себя compose. Напишем и её тоже. Для начала обратимся к шаблону, который создали ранее, и вытащим его содержимое. В нашем случае содержимым будет «скелет» свита, элемент <article>. Укажем, что нам необходимо его склонировать, а не использовать сам элемент, иначе он изменится сам, и мы не сможем сделать несколько свитов. Теперь получаем всю необходимую информацию из post. Затем добавляем соответствующие тексты и числа в нужные места в «скелете». В конце возвращаем созданный элемент, чтобы его можно было добавить на страницу.
function composePost(postData) { // Если ничего не передано, ничего не возвращаем if (!postData) return // Обращаемся к старому шаблону const template = document.getElementById('post_template') // Клонируем const post = template.content.cloneNode(true) // Получаем нужную информацию const { title, body, likes, reposts } = postData // Добавляем соответствующие тексты и числа post.querySelector('h1').innerText = title post.querySelector('p').innerText = body post.querySelector('button:first-child').innerText += likes post.querySelector('button:last-child').innerText += reposts // Возвращаем созданный элемент return post}
function composePost(postData) {
// Если ничего не передано, ничего не возвращаем
if (!postData) return
// Обращаемся к старому шаблону
const template = document.getElementById('post_template')
// Клонируем
const post = template.content.cloneNode(true)
// Получаем нужную информацию
const { title, body, likes, reposts } = postData
// Добавляем соответствующие тексты и числа
post.querySelector('h1').innerText = title
post.querySelector('p').innerText = body
post.querySelector('button:first-child').innerText += likes
post.querySelector('button:last-child').innerText += reposts
// Возвращаем созданный элемент
return post
}
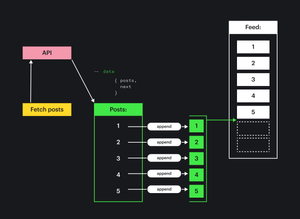
Представить это можно как цепочку событий: запрашиваем данные, получаем ответ, для каждого поста наполняем шаблон данными, получившиеся элементы встраиваем на страницу.
В реальном приложении нам бы потребовалось ещё повесить обработчики кликов по кнопкам в этом новом свите. Без обработчиков кнопки не будут ничего делать. Но для краткости эту часть в статье мы опустим.
Добавим обработку данных в fetch:
async function fetchPosts() { const { posts, next } = await server.posts(nextPage) posts.forEach(appendPost)}
async function fetchPosts() {
const { posts, next } = await server.posts(nextPage)
posts.forEach(appendPost)
}
Осталось лишь правильно обработать случаи, когда мы отправили запрос и ждём ответа, и когда контент закончился.
Обработка промежуточных и крайних случаев
СкопированоЕсли сейчас запустить приложение, то оно будет работать. Но при прокрутке к концу страницы вместо одной порции контента будет присылать несколько. (И никогда не закончит это делать 😁)
Чтобы решить эти проблемы, нужно завести переменные, которые будут следить за состоянием приложения. Узнаем, какая страница следующая. Если отправили запрос, но ещё не получили ответ, не нужно отправлять ещё один запрос. Если контент закончился, вообще больше не нужно отправлять никаких запросов.
// Следующая страницаlet nextPage = 2// Не отправляем ещё один запросlet isLoading = false// Больше не отправляем никаких запросовlet shouldLoad = true
// Следующая страница
let nextPage = 2
// Не отправляем ещё один запрос
let isLoading = false
// Больше не отправляем никаких запросов
let shouldLoad = true
Подправим функцию fetch. Если мы уже отправили запрос, или новый контент закончился, то новый запрос отправлять не надо. Дополнительно хорошо предотвращать новые запросы, пока не закончится текущий. После запрашиваем страницу с номером next. Если увидели, что контент закончился, отмечаем, что больше запрашивать ничего не надо. Наконец, когда запрос выполнен и обработан, снимем флаг is.
async function fetchPosts() { // Не отправляем новый запрос if (isLoading || !shouldLoad) return // Предотвращаем новые запросы isLoading = true const { posts, next } = await server.posts(nextPage) posts.forEach(appendPost) // Следующая страница nextPage = next // Больше не надо ничего запрашивать if (!next) shouldLoad = false // Снимаем флаг isLoading = false}
async function fetchPosts() {
// Не отправляем новый запрос
if (isLoading || !shouldLoad) return
// Предотвращаем новые запросы
isLoading = true
const { posts, next } = await server.posts(nextPage)
posts.forEach(appendPost)
// Следующая страница
nextPage = next
// Больше не надо ничего запрашивать
if (!next) shouldLoad = false
// Снимаем флаг
isLoading = false
}
Теперь функция работает правильно.
Что можно улучшить ещё
СкопированоМы создали базовую функциональность подгрузки, но есть ряд улучшений, о которых стоит помнить в реальном приложении. Они чаще всего сложны в реализации, поэтому в этом подразделе мы поговорим о таких улучшениях, но не будем реализовывать их.
Изменение адресной строки
СкопированоХорошим тоном считается, когда мы можем дать ссылку на публичную страницу, и другой человек увидит всё в точности, как мы: сортировку контента, его количество, начало и конец. Для этого используется адресная строка и URL-страницы.
В нашем случае при изменении номера текущей страницы мы можем изменять часть адреса.
Восстановление прокрутки при открытии страницы
СкопированоПри открытии страницы нам надо будет проверить адрес. Если там указано, что нам нужно «прокрутить» контент к какой-то странице, мы это сделаем программно.
Эту задачу часто решают на сервере. Это может быть проще и эффективнее, потому что сервер в таком случае заранее знает, какие данные нужно достать и отдать клиенту. Получается меньше запросов, и приложение для пользователя субъективно быстрее.
Результат
СкопированоВ результате мы получим переработанную страницу Switter, которая будет получать контент в тот момент, когда он нужен пользователю.
На практике
Скопированосоветует
Скопировано🛠 Используйте throttle для подобных задач, чтобы улучшать производительность.
Читайте также
-

Что такое API
Как разговаривать с инопланетянами? А с программой, написанной на другом языке? Просто добавь API.
-

Как работают веб-приложения
История развития веб-приложений или зачем нам бэкенд.
-

Безопасность веб-приложений и распространённые атаки
Интернет доступен всем — даже мошенникам и хакерам. Разбираем распространённые атаки на сайты и веб-приложения.