Кратко
СкопированоЛюбые текстовые данные в JavaScript — это строки (англ. string). Строки представляют собой последовательность символов. Созданная строка является иммутабельной (immutable) и не может быть изменена.
Как пишется
СкопированоЕсть несколько способов создать строку:
- одинарными кавычками
'; - двойными кавычками
"; - шаблонной строкой через обратный апостроф
`.
Записи одинарными и двойными кавычками идентичны:
const double = "Окна были распахнуты настежь, и булыжник мостовой просыхал после дождя."const single = 'Солнце высушивало мокрые лица домов напротив моего окна'
const double = "Окна были распахнуты настежь, и булыжник мостовой просыхал после дождя."
const single = 'Солнце высушивало мокрые лица домов напротив моего окна'
Можно создать пустую строку или строку из пробелов:
const empty = ''const spaces = ' '
const empty = ''
const spaces = ' '
Если в записи одинарными кавычками нужно поставить апостроф, то символ экранируют обратным слэшем \. Так мы даём JavaScript понять, что это просто символ, а не закрывающая кавычка:
const who = 'I\'m a good person.'
const who = 'I\'m a good person.'
Шаблонные строки позволяют подставлять в строку значения переменных. Между обратными апострофами пишется текст, а в местах, где нужно вставить значение из переменной используется синтаксис ${имя:
const product = 'Штаны'const qty = 1console.log(`Набор программиста: ${product}, ${qty}шт.`)// Набор программиста: Штаны, 1шт.
const product = 'Штаны'
const qty = 1
console.log(`Набор программиста: ${product}, ${qty}шт.`)
// Набор программиста: Штаны, 1шт.
Детальное описание работы с шаблонными строками, читайте в статье «Шаблонные строки».
Как понять
СкопированоСтрока сложно устроена внутри, несмотря на то, что это примитив. Визуально текст представляет собой последовательность символов, но как компьютер хранит эти символы?
Символ, который видно на экране хранится в компьютере как одно или несколько чисел, каждое такое число называют юнитом. Компьютер хранит таблицу в которой числу соответствует символ. Такие таблицы называют кодировкой.
В JavaScript используется кодировка UTF-16, самая распространённая в мире. Таблица этой кодировки настолько большая, что покрывает не только все современные алфавиты и иероглифические системы записи, но и шумерскую клинопись, и древнеегипетские иероглифы. Эмодзи тоже содержатся в этой таблице, поэтому нам не нужно ничего устанавливать на компьютер чтобы видеть их 🙌
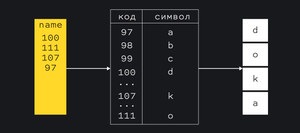
Отдельный символ строки можно получить по порядковому номеру символа в строке, он начинается с 0:
const greeting = 'Привет!'console.log(greeting[0])// Пconsole.log(greeting[3])// в
const greeting = 'Привет!'
console.log(greeting[0])
// П
console.log(greeting[3])
// в
Операции со строками
СкопированоДля строк определена операция сложения, её также называют конкатенацией строк. При сложении двух строк получается новая строка, склеенная из исходных:
const desire = 'Я хочу'const food = 'пельменей'const bad = desire + foodconsole.log(bad)// Я хочупельменейconst good = desire + ' ' + foodconsole.log(good)// Я хочу пельменей
const desire = 'Я хочу'
const food = 'пельменей'
const bad = desire + food
console.log(bad)
// Я хочупельменей
const good = desire + ' ' + food
console.log(good)
// Я хочу пельменей
Строки можно сравнивать между собой, для сравнения используется лексикографический порядок. Это означает, что первые символы алфавита считаются меньше последних.
Алгоритм посимвольно сравнивает строки до первого несовпадения, либо пока не закончится одна из строк. Например, для произвольных строк s1 и s2:
- Сравниваются символы
s1и[ 0 ] s2. Если символы разные, то большей будет та строка, символ которой больше. Сравнение завершено.[ 0 ] - Если первые символы совпали, аналогично проверяем вторые символы. Продолжаем, пока не найдём несовпадение или не закончится одна из строк.
- Если строки закончились одновременно, то они равны. Если закончилась одна из строк, то большей строкой считается строка с большим количеством символов.
console.log('А' > 'Я')// falseconsole.log('Кот' > 'Код')// trueconsole.log('Код' > 'Кодер')// falseconsole.log('Код' === 'Код')// true
console.log('А' > 'Я')
// false
console.log('Кот' > 'Код')
// true
console.log('Код' > 'Кодер')
// false
console.log('Код' === 'Код')
// true
Сравнение учитывает регистр букв, если необходимо регистронезависимое сравнение, то обе строки приводятся к верхнему или нижнему регистру с помощью методов to или to:
const capitalized = 'Арбуз'const lowercased = 'арбуз'console.log(capitalized === lowercased)// falseconsole.log(capitalized.toLowerCase() === lowercased.toLowerCase())// true
const capitalized = 'Арбуз'
const lowercased = 'арбуз'
console.log(capitalized === lowercased)
// false
console.log(capitalized.toLowerCase() === lowercased.toLowerCase())
// true
Специальные символы
СкопированоКогда компьютеры только появились, главным способом взаимодействия с компьютером был текст. Неформатированный текст сложно воспринимать, поэтому появились специальные символы, которые обозначали различные операции, которые нужно сделать с текстом при выводе на экран.
На сегодняшний день актуальными остаются два таких символа:
\n— начало новой строки;\t— табуляция, аналогично нажатию кнопки Tab.
Если эти символы есть в строке, то при печати на экран будет выполнено указанной действие:
const phrase = 'Мы —\n\tЭдисоны\n\t\tневиданных взлётов,\n\t\t\tэнергий\n\t\t\t\tи светов.'console.log(phrase)// Мы —// Эдисоны// невиданных взлётов,// энергий// и светов.
const phrase = 'Мы —\n\tЭдисоны\n\t\tневиданных взлётов,\n\t\t\tэнергий\n\t\t\t\tи светов.'
console.log(phrase)
// Мы —
// Эдисоны
// невиданных взлётов,
// энергий
// и светов.
Длина строки
СкопированоЧасто используемая операция над строкой — получение её длины:
const str = 'Строка текста неизвестной длины'console.log(str.length)// 31
const str = 'Строка текста неизвестной длины'
console.log(str.length)
// 31
Эта операция может вернуть неверное количество символов в строке в тех случаях, когда используются эмодзи. Такой пример рассмотрен в статье о свойстве length строки.
Дополнительные методы
СкопированоСам по себе примитивный тип «строка» не имеет методов. Когда происходит вызов метода, оно автоматически оборачивается в специальную обёртку, которая и содержит методы:
const lowercased = 'арбуз'console.log(lowercased.toUpperCase())// АРБУЗ
const lowercased = 'арбуз'
console.log(lowercased.toUpperCase())
// АРБУЗ
Методы обёртки часто используются, они подробно описаны в отдельной статье.
На собеседовании
Скопировано отвечает
СкопированоКак должна работать функция?
СкопированоДля начала вспомним, что принимает и возвращает эта функция:
String.prototype.indexOf(searchString [, position]): number
String.prototype.indexOf(searchString [, position]): number
Где:
search— строка в которой нужно искать.String position— индекс элемента, с которого начинается поиск.
Реализация
СкопированоЧтобы реализовать такой поиск воспользуемся скользящим окном, а точнее его частной реализацией, алгоритмом Рабина-Карпа.
Скользящее окно — это алгоритм, который использует область фиксированной длины внутри массива. Двигая эту область, можно получать данные о группе рядом стоящих элементов массива. В нашем случае длина окна будет равна длине подстроки, по которой производится поиск.
// string - строка по которой ведем поиск// substr - подстрока, которую ищем// pos - стартовая позицияfunction myIndexOf(string, substr, pos = 0) { // запускаем цикл, от pos до (конца_строки - длина_окна) for (let i = pos; i < string.length - substr.length + 1; i++) { // если наша подстрока === содержимому окна, то заканчиваем работу и возвращаем index if (substr === string.substr(i, substr.length)) { return i; } } // Если ничего не найдено, то возвращаем -1 return -1;}
// string - строка по которой ведем поиск
// substr - подстрока, которую ищем
// pos - стартовая позиция
function myIndexOf(string, substr, pos = 0) {
// запускаем цикл, от pos до (конца_строки - длина_окна)
for (let i = pos; i < string.length - substr.length + 1; i++) {
// если наша подстрока === содержимому окна, то заканчиваем работу и возвращаем index
if (substr === string.substr(i, substr.length)) {
return i;
}
}
// Если ничего не найдено, то возвращаем -1
return -1;
}
Что может пригодится на собеседовании
СкопированоСложность такого алгоритма O(mn), где n — длина string, а m — длина substr. Чтобы улучшить его можно реализовать hash, чтобы сравнивать не 2 подстроки, а их hash. Подробнее о hash функциях.
function myIndexOf(string, substr, pos = 0) { if (pos + substr.length > string.length) return -1 const hashPattern = hash(substr) // hash - абстрактная функция взятия хэша, тут я не буду приводить пример её реализации for (let i = pos; i < string.length - substr.length + 1; i++) { // Чтобы 2жды не брать подстроку сохраняем её const windowContent = string.substr(i, substr.length); // Проверяем совпадают ли хэши if (hashPattern === hash(windowContent)) { // Необходимо удостоверится, что нет коллизий и проверить посимвольное совпадение if (substr === windowContent) { return i; } } } return -1;}
function myIndexOf(string, substr, pos = 0) {
if (pos + substr.length > string.length) return -1
const hashPattern = hash(substr) // hash - абстрактная функция взятия хэша, тут я не буду приводить пример её реализации
for (let i = pos; i < string.length - substr.length + 1; i++) {
// Чтобы 2жды не брать подстроку сохраняем её
const windowContent = string.substr(i, substr.length);
// Проверяем совпадают ли хэши
if (hashPattern === hash(windowContent)) {
// Необходимо удостоверится, что нет коллизий и проверить посимвольное совпадение
if (substr === windowContent) {
return i;
}
}
}
return -1;
}
В худшем случае новый алгоритм работает за O(mn), но если функция взятия хэша написана достаточно хорошо, то нам не придётся часто проверять условие substr и в среднем случае сложность будет стремиться к O(n). Это происходит, потому что hash — полиномиальный, то есть мы можем из предыдущего хэша, вычислить следующий за O(1), по сути прибавить следующий и отнять предыдущий символ. Проблема только в том, что разные строки могут выдавать одинаковые хэши. Для этого, мы вводим дополнительную проверку после сравнения хэша. Если же нам не нужен гарантированный результат правильной работы функции, то можно вовсе убрать строку со сравнением substr и сразу возвращать результат. Тогда алгоритм всегда будет работать за O(n).
Немного о других алгоритмах
Существует также множество других алгоритмов, которые гарантированно делают поиск O(n), к примеру, один из таких алгоритмов используется в движке браузера V8, однако, они сложнее и о них мало кто знает, так что если вы не сидите на собеседовании на должность преподавателя Алгоритмов, то вам вряд ли они пригодятся. Для ознакомления предоставлю несколько из таких:
отвечает
СкопированоЗначение этого выражения в JavaScript будет "искат ьтакси". Почему?
- Вызов "искать такси".split('') разделяет строку на массив символов: "и", "с", "к", "а", "т", "ь", " ", "т", "а", "к", "с", "и".
- Вызов reverse() переворачивает порядок элементов в массиве: "и", "с", "к", "а", "т", " ", "ь", "т", "а", "к", "с", "и".
- Вызов join('') объединяет элементы массива в строку, используя пустую строку в качестве разделителя: "искат ьтакси".
отвечает
СкопированоЧто такое стратегия?
СкопированоСтратегия (Strategy) — это ООП поведенческий шаблон проектирования, который позволяет расширять базовый класс или метод новым функционалом. Для этого нужно передать в него, так называемый, конкретный класс. Например:
const Clock = new Clock // Создаем базовую версию часовconst GoldenClock = new Clock(new GoldenParts) // Часы с золотым оформлениемconst WoodenClock = new Clock(new WoodenParts) // Часы с деревянным оформлениемClock.draw() // Рисуем стандартную версию часовGoldenClock.draw() // Метод тот же, что и строкой выше, но теперь мы используем золотое оформлениеWoodenClock.draw() // Используем деревянное оформление
const Clock = new Clock // Создаем базовую версию часов
const GoldenClock = new Clock(new GoldenParts) // Часы с золотым оформлением
const WoodenClock = new Clock(new WoodenParts) // Часы с деревянным оформлением
Clock.draw() // Рисуем стандартную версию часов
GoldenClock.draw() // Метод тот же, что и строкой выше, но теперь мы используем золотое оформление
WoodenClock.draw() // Используем деревянное оформление
Выполнение задачи
СкопированоЧтобы написать такой класс нам понадобится специальный well-known символ [. Метод split вызывает функцию [, а результат вызова возвращает как результат split. У строк это уже реализовано:
"123,4,56".split(",") // ["123", "4", "56]
"123,4,56".split(",") // ["123", "4", "56]
Мы можем добавить такое же поведение к своему классу:
class MySplit { constructor(value) { this.value = value; // Принимаем строку по которой будем сплитить } [Symbol.split](string) { // принимаем строку-аргумент (которую будем сплитить) // В конце необходимо вернуть полученный результат, иначе split() вернет undefined }}
class MySplit {
constructor(value) {
this.value = value; // Принимаем строку по которой будем сплитить
}
[Symbol.split](string) { // принимаем строку-аргумент (которую будем сплитить)
// В конце необходимо вернуть полученный результат, иначе split() вернет undefined
}
}
Для нашей задачи разобьём строку при помощи регулярного выражения:
[Symbol.split](string) { // Заменяем все вхождения this.value на /${this.value}/ let index = string.replace(new RegExp(this.value, "g"), `/${this.value}/`); // убираем первый слэш, /url/Path -> url/Path if (index[0] === "/") index = index.substr(1) // Строка должна начинаться с url/, даже если его не было в начале if (!index.startsWith(this.value)) index = `${this.value}/` + index; return index;}
[Symbol.split](string) {
// Заменяем все вхождения this.value на /${this.value}/
let index = string.replace(new RegExp(this.value, "g"), `/${this.value}/`);
// убираем первый слэш, /url/Path -> url/Path
if (index[0] === "/") index = index.substr(1)
// Строка должна начинаться с url/, даже если его не было в начале
if (!index.startsWith(this.value)) index = `${this.value}/` + index;
return index;
}
Пример работы
Скопировано
"foobarfoobaz".split(new MySplit("foo")) // "foo/bar/foo/baz""foobarfoobaz".split(new MySplit("bar")) // "bar/foo/bar/foobaz"
"foobarfoobaz".split(new MySplit("foo")) // "foo/bar/foo/baz"
"foobarfoobaz".split(new MySplit("bar")) // "bar/foo/bar/foobaz"
Что хотят проверить?
СкопированоЭтот вопрос проверяет умеете ли вы использовать символы. Хотя такие вопросы задают редко, из-за специфичности темы, умение пользоваться символами – полезный инструмент, который вам обязательно пригодится.
отвечает
СкопированоИз всех способов преобразования строки в число, использование унарного оператора +str — самый быстрый, потому что не требует математических или других операций.
Можно проверить и сравнить результаты различных способов преобразования на MeasureThat.net.
отвечает
СкопированоЕсть несколько способов явного преобразования строки в число. Рассмотрим примеры:
const str = '42'// 1. Функция `Number()`const num1 = Number(str)// 2. Методы `Number.parseInt()` и `Number.parseFloat()`const num2 = Number.parseInt(str)const num3 = Number.parseFloat(str)// 3. Унарный плюс (оператор `+`)const num4 = +str// 4. Унарный минус (оператор `-`)const num5 = -str
const str = '42'
// 1. Функция `Number()`
const num1 = Number(str)
// 2. Методы `Number.parseInt()` и `Number.parseFloat()`
const num2 = Number.parseInt(str)
const num3 = Number.parseFloat(str)
// 3. Унарный плюс (оператор `+`)
const num4 = +str
// 4. Унарный минус (оператор `-`)
const num5 = -str
Использование унарного плюса является самым быстрым способом преобразования строки в число, так как при этом не выполняются никакие дополнительные действия.
Единственный недостаток применения унарного плюса по сравнению с использованием функции Number — работа со значениями типа Big. При попытке преобразовать с помощью оператора + строку с Big-значением в число, будет брошена ошибка Type.
Читайте также
-

Преобразование типов
Брюки превращаются в элегантные шорты, а во что превращается строка «55ab» при преобразовании в число?
-

Стиль написания кода в команде
Превратить хороший код проекта в нечитаемую кашу можно очень легко, если не договориться о форматировании.