Зачем мне понимать модели памяти?
СкопированоПри изучении нового языка программирования, вы быстро напишите свой первый Hello и начнёте использовать переменные.
Но что действительно происходит при создании или присваивании переменных, и как выполняются функции? Во всех этих процессах участвует память. Если вы примерно поймёте, как она устроена, будет значительно проще использовать инструменты разработчика и легче ответить на вопросы, связанные с памятью.
Древние модели памяти
СкопированоВ давние времена, когда компьютеры только изобретали, было предложено две модели их устройства:
Эти архитектуры во многом схожи: процессор выполняет различные операции с данными. Какую именно операцию выполнить определяет инструкция. Инструкции и данные поступают к процессору из памяти. Память разделена на ячейки, каждая ячейка заботливо пронумерована. Номер ячейки называется адресом в памяти. Адрес — величина фиксированной длинны. Процессор может обращаться к любой ячейке, не обязательно делать это по порядку. Если данные не влезают в одну ячейку, их можно разместить в нескольких.
Основное отличие между этими моделями заключается в том, как именно хранятся инструкции и данные. В Гарвардской модели данные и инструкции разделены, а в архитектуре Фон Неймана они помещаются в одно хранилище. Это значит, что процессор, который использует данные и инструкции, будет доставать их одинаковым способом — с помощью одной шины. Используйте архитектуру Фон Неймана как ментальную модель, чтобы представить себе, что происходит в памяти, когда запускается программа.
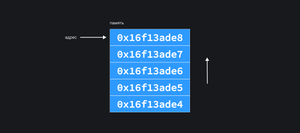
Модели памяти. Чуть ближе к реальности
СкопированоМодель выше хорошо подходит для рассуждений о работе программы. В реальности всё немного сложнее. Адреса, на которые смотрели в предыдущем разделе, — виртуальные. Чтобы обратиться к реальному адресу, вашему процессору нужно превратить виртуальный адрес в физический адрес ячейки оперативной памяти.
Когда процессу требуется память, операционная система выдаёт процессу блок памяти, называемый страницей (page). Обычно размер страницы относительно небольшой — 4–8 Кб. Процессу можно выдавать много страничек. Эти страницы — виртуальные кусочки памяти, которые как-то отображаются на физическую память.
Кто и как использует память
СкопированоОперационная система запускает программу в рамках определённого процесса. Для этого процесса выделяются ресурсы и адресное пространство – то, какие адреса памяти может использовать данный процесс. Операционная система гарантирует, что один процесс не будет иметь доступа к памяти другого процесса, если другой процесс этого не разрешит.
В рамках процесса может существовать один или несколько потоков. Для каждого потока выделяется кусочек памяти.
В этот кусочек памяти загружается код программы, глобальные переменные и ещё кое-что. В этом же кусочке памяти выделяются две важные области: стек (stack) и куча (heap). Стек — это область памяти, которую очень легко выделять.
Данные на стеке можно читать. Данные нужно «положить» на стек, чтобы их записать. Вы не можете записать данные в произвольную область стека, только в конец. Также не можете удалить данные из произвольной области стека, однако возможно перемотать указатель стека. Это равносильно удалению всех данных.
Программа в процессе выполнения активно работает со стеком. Память для стека может закончиться, тогда возникнет всем известное переполнение стека (stack overflow).
Очень популярная и известная картинка, которая объясняет всё:
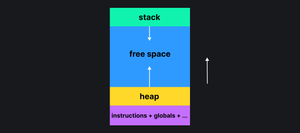
Стек и куча растут навстречу друг другу 🤗
Что происходит со стеком
СкопированоДавайте посмотрим на функцию подсчёта собачек count. Она принимает один аргумент — happy, создаёт внутри переменную sad и как-то считает количество собачек.
function countDogs(happyDogs) { const sadCoefficient = 0.1; return happyDogs + sadCoefficient * happyDogs;}
function countDogs(happyDogs) {
const sadCoefficient = 0.1;
return happyDogs + sadCoefficient * happyDogs;
}
Чтобы выполнить эту функцию, нужно положить аргументы функции и локальные переменные на стек. Кроме этого, нужно понимать, какой код выполнить после того, как функция завершится. Для этого на стеке создаётся stack_frame. В нём хранятся аргументы и локальные переменные. После того как функция выполнится, стек фрейм удаляется вместе со всем аргументами и переменными функции. При создании стек фрейма используется ещё одна полезная штука – указатель на фрейм (frame pointer). Этот указатель всегда указывает на активный фрейм на стеке.
Давайте посмотрим, что произойдёт, если захотим посчитать собачек в консоли.
function logDogs() { console.log(countDogs(20), countDogs(9));}logDogs();
function logDogs() {
console.log(countDogs(20), countDogs(9));
}
logDogs();
- На стеке создастся фрейм для функции
log.Dogs ( ) - Потом добавится фрейм для первого вызова
count.Dogs ( 20 ) - После выполнения функции
countфрейм удаляется.Dogs ( 20 ) - Потом добавится фрейм для второго вызова
count.Dogs ( 9 ) - После выполнения функции
countфрейм удаляется.Dogs ( 9 ) - После выполнения функции
logфрейм удаляется.Dogs ( )
Фрейм для функции count будет содержать аргумент функции (20) и локальную переменную (sad).
Если в процессе выполнения функции код выбросит ошибку, то произойдёт разматывание стека (stack unwinding). Вы увидите в консоли знакомый stack trace.

Давайте модифицируем функцию count и заставим её выкинуть ошибку.
function countDogs(happyDogs) { const sadCoefficient = 0.1; if (happyDogs < 10) { throw new Error('Слишком мало весёлых собачек!'); } return happyDogs + sadCoefficient * happyDogs;}
function countDogs(happyDogs) {
const sadCoefficient = 0.1;
if (happyDogs < 10) {
throw new Error('Слишком мало весёлых собачек!');
}
return happyDogs + sadCoefficient * happyDogs;
}
Получим следующий результат, когда запустим код из этого примера в консоли браузера:
Uncaught Error: Слишком мало весёлых собачек!
at countDogs (<anonymous>:4:11) <-- вот фрейм count dogs
at logDogs (<anonymous>:2:30) <-- вот фрейм logDogs
at <anonymous>:1:1
Увидим при разматывании стека, что сначала будет удалён фрейм count, а потом log. После этого выполнение кода прекратится.
Зачем нужна куча?
СкопированоДанные на стеке хранятся не долго. Когда функция завершает своё выполнение, то все данные удаляются. Кроме этого, вы не можете положить на стек данные произвольного размера.
Рассмотрим функцию работы с массивом create.
function createDogArray() { const dogs = ['🐶', '🐶', '🐶']; // 3 элемента if (Math.random() > 0.5) { dogs.push('🐶'); // а может и 4 элемента :) }}
function createDogArray() {
const dogs = ['🐶', '🐶', '🐶']; // 3 элемента
if (Math.random() > 0.5) {
dogs.push('🐶'); // а может и 4 элемента :)
}
}
Мы создали массив из 3 элементов. Теперь нужно положить на стек переменную dogs, которая содержит этот массив. Для этого нужно выделить место под переменную. Всё было хорошо, пока мы не решили случайным образом добавить ещё одну собачку. Получается, что количество элементов в массиве dogs неизвестно, и непонятно, сколько памяти под него нужно выделить.
Вот как куча решает эту проблему: выделятся специальный кусочек памяти под массив. Адрес этого кусочка в памяти запоминается и «записывается» в dogs. Как мы знаем, адрес имеет фиксированный размер, так что сможем положить переменную dogs с адресом на стек. Когда понадобится модифицировать массив, возьмём адрес в куче, найдём по этому адресу массив и добавим в него новую собачку.
Упражнение, упражнение!
СкопированоТеперь вы представляете как устроена память и готовы ответить на вопросы из начала статьи.
Если у вас получилось, приносите ответы в раздел «На собеседовании».
На собеседовании
Скопировано отвечает
СкопированоВопрос в такой постановке не имеет однозначного ответа.
Прежде всего вспомним, какие типы языков, в зависимости от способа трансляции (компиляции) исходного кода в машинный код, бывают:
- компилируемые;
- интерпретируемые.
У компилируемого языка этап трансляции исходного кода происходит до выполнения. Это требует анализа всей написанной программы целиком, однако позволяет выявить многие ошибки. К таким языкам относятся C, C++, Go.
У интерпретируемых языков трансляция происходит «на лету» (строка за строкой). Такой подход обеспечивает дополнительную гибкость и динамические изменения на этапе выполнения и требует меньше времени для старта. К интерпретируемым языкам относят «скриптовые» языки: Perl, VBScript, PHP.
JavaScript иногда называют интерпретируемым, что верно лишь отчасти. Например, если мы сделали опечатку в названии константы, программа выполнится до строки с ошибкой:
const a = 0console.log("1-ая строка выполнена")console.log(a2)// 1-ая строка выполнена// console.log(a2)// ^// ReferenceError: a2 is not defined
const a = 0
console.log("1-ая строка выполнена")
console.log(a2)
// 1-ая строка выполнена
// console.log(a2)
// ^
// ReferenceError: a2 is not defined
В то же время JavaScript нельзя назвать интерпретируемым.
Попытаемся выполнить программу, содержащую синтаксическую ошибку во второй строке:
console.log("1-ая строка выполнена")console.log("2-ая строка содержит ошибку"")// SyntaxError: Invalid or unexpected token
console.log("1-ая строка выполнена")
console.log("2-ая строка содержит ошибку"")
// SyntaxError: Invalid or unexpected token
Можно было ожидать, что сначала выполнится первая строка, а затем выведется сообщение об ошибке, но при выполнении получаем только сообщение об ошибке (текст сообщения зависит от движка, в примере приведён результат работы в Node.js).
Ещё один пример, опровергающий построчную интерпретацию исходного кода в JavaScript — «поднятие» (hoisting) при объявлении функций:
praise("Пушкин")// Ай да, Пушкин!function praise(name) { console.log(`Ай да, ${name}!`)}
praise("Пушкин")
// Ай да, Пушкин!
function praise(name) {
console.log(`Ай да, ${name}!`)
}
Современные движки JavaScript используют JIT (just-in-time) компиляцию - подход, позволяющий оптимизировать код. Говоря простым языком, идея заключается в наблюдении за тем, сколько раз выполняется определённая часть кода и какие типы данных при этом используются.
На первом этапе используется интерпретатор. Если какая-то часть кода, например функция, выполняется многократно, то для неё будет использована компиляция и попытка оптимизации.
Подводя итог, можно сказать, что JavaScript не относится полностью ни к компилируемым, ни к интерпретируемым языкам.
Это вопрос без ответа. Вы можете помочь! Чтобы написать ответ, следуйте инструкции.
Читайте также
-

Порядок выполнения
JavaScript выполняет код в определённой последовательности. Разбираемся, в какой, и как это можно менять.